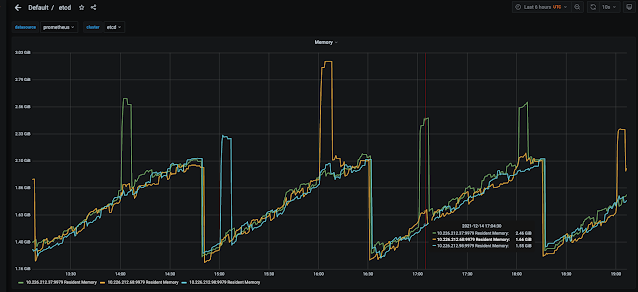
A colleague recently approached me about some cyclical etcd memory usage on their OpenShift clusters. The pattern appeared to be a “sawtooth” or “run and jump” pattern when looking at the etcd memory utilization graphs. The pattern happened every two hours where over the course of the two hours memory usage would gradually increase and then roughly at the two hour mark would abruptly drop back down to a more baseline level before repeating. My colleague wanted to understand why this behavior was occurring and what was causing the memory to be freed. In order to answer this question we first need to explore a little more about etcd and what things impact memory utilization and allow for free pages to be returned.

Etcd can be summarized as a distributed key-value data store in OpenShift designed to be highly available and strongly consistent for distributed systems. OpenShift uses etcd to store all of its persistent cluster data, such as configs and metadata, allowing OpenShift services to remain scalable and stateless.Etcd’s datastore is built on top of a fork of BoltDB called BBoltDB. Bolt is a key-value store that writes its data into a single memory mapped file which enables the underlying operating system to handle how data is cached and how much of the file remains in memory. The underlying data structure for Bolt is B+ tree consisting of 4kb pages that are allocated as they are needed. It should be noted that Bolt is very good with sequential writes but weak with random writes. This will make more sense further in this discussion.
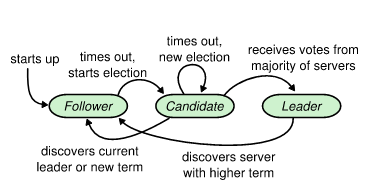
Along with Bolt in etcd is a protocol called Raft which is a consensus algorithm that is designed to be easy to understand and provide a way to distribute a state machine across a cluster of distributed systems. Consensus, which involves a simple majority of servers agreeing on values, can be thought of as a highly available replication log between the nodes running etcd in the OpenShift cluster. Raft works by electing a leader and then forcing all write requests to go to the leader. Changes are then replicated from the leader to the other nodes in the etcd cluster. If by chance the leader node goes offline due to maintenance or failure Raft will hold another election for a leader.
Etcds uses multiversion concurrency control (MVCC) in order to handle concurrent operations from different clients. This ties into the Raft protocol as each version in MVCC relates to an index in the Raft log. Etcd manages changes by revisions and thus every transaction made to etcd is a new revision. By keeping a history of revisions, etcd is able to provide the version history for specific keys. These keys are then in turn associated with their revision numbers along with their new values. It's this key writing scheme that enabled etcd to make all writes sequential which reduces reliability on Bolts weakness above at random writes.
As we discussed above, etcd use of revisions and key history enables useful features for a key or set of keys. However, etcds revisions can grow very large on a cluster and consume a lot of memory and disk. Even if a large number of keys are deleted from the etcd cluster the space will continue to grow since the prior history for those keys will still exist. This is where the concept of compaction comes into play. Compaction in etcd will drop all previous revisions smaller than the revision being compacted to. These compactions are just deletions in Bolt but they do remove keys from memory which will free up memory. However if those keys have also been written to disk the disk will not be freed up until a defrag which can reclaim the space.
Circling back to my colleague's problem, I initially thought maybe a compaction job every two hours was the cause of his “sawtooth” graph of memory usage. However it was confirmed that his compaction job was configured to run every 5 minutes. This obviously did not correlate to the behavior we were seeing in the graphs.
Then I recalled, besides storing configs and metadata, etcd also stores events from the cluster. These events would be stored just like we described above in key value pairs and would have revisions. Although events would most likely never have new revisions because each event would be a unique key value pair. Now every cluster event has an event-ttl assigned to it. The event-ttl is just like one would imagine, a time to live before the event is removed or aged out. The thought was maybe we had a persisting grouping of events happening that would age out over the time frame pattern we were seeing in the memory usage. However upon investigating further we found the event-ttl was set to three hours. Given our pattern was at a two hour scenario we abandoned looking any further at that option.
Then as I was looking through documentation about etcd I recalled that Raft with all of its responsibilities in etcd also does a form of compaction. If we recall from above I indicated Raft has a log which contains indexes which just happens to be memory resident. In etcd there is a configuration option called snapshot-count which controls the number of applied Raft entries to hold in memory before compaction executes. In versions of etcd before v.3.2 that count was 10k but in v3.2 or greater the value has been set to 100k so ten times the amount of entries. When the snapshot count on the leader server is reached the snapshot data is persisted to disk and then the old log is truncated. If a slow follower requests logs before a compacted index is complete the leader will send a snapshot for the follower to just overwrite its state. This was exactly the explanation for the behavior we were seeing.
Hopefully this walk through provided some details on how etcd works and how memory is impacted on a running cluster. To read further on any of the topics feel free to explore these links: